TaskGraphとSchedulerを理解する
を調べた結果、おおむねスケジューラーの全体像が見えてきましたが、 各ヴァーチャル関数の関係性や、WorkItemとの関係性が見えてきません。 ので、今回はその関係性を理解するうえで重要なDependencyGraphについて調べていこうと思います。
TOP Network について
TOP Network は /tasks 以下に TOP Network ノードを作ると使用できます。
このノード内に複数のノードを作ることはできますが、基本 1 つの処理のまとまり= TOP Network として作成します。

TOP Network 内のノードは、ノードと、WorkItem で構成されています。
ノードは、GenericGenerator2 や、PythonScript2 のようなある処理を実行するための構造(処理のテンプレート的なもの)を言います。
対して、実際に実行するのは WorkItem と呼ばれる緑の〇ポチです。
この WorkItem は、実行するタスクのパラメーター(アトリビュート)の集合体です。
この WorkItem は、いわゆる関数の引数のようなもの、その引数を渡してある処理を実行する
というのが基本的なノードと WorkItem の関係性です。

この WorkItem は、関係性を定義することができます。
たとえば、前の工程の成果物を受け取り、次の工程で実行したい...というのはよくあることです。
このような、実行したときの結果を受け渡す場合、WorkItem には output / input という特殊なアトリビュートを追加することができます。
( このあたり参考)
個のアトリビュートは、WorkItem の依存関係を使用して
いい感じに受けわたしできるようになっています。
Generate
上で書いた TOP Network の WorkItem は、「Generate」することで生成されます。
Generate とは、あくまでも WorkItem を生成するだけで、実際には実行しません。
生成時は、TOP Network 内のプロセッサーノードによってノードのアトリビュートと
前ノードの接続情報をもとに事前に生成されます。
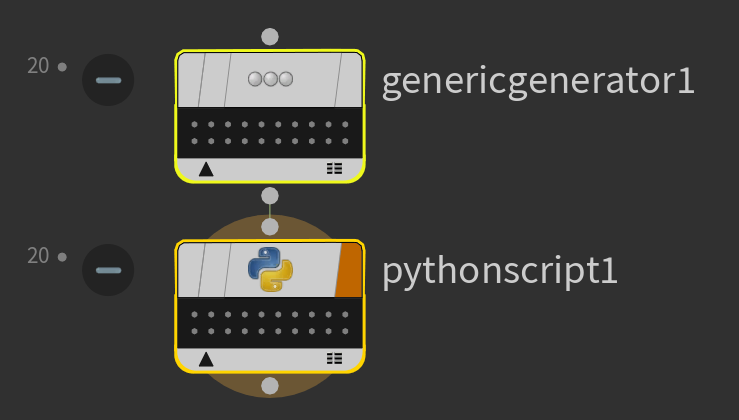
例として GenericGenerator を使用した例。
GenericGenerator は Item Count で指定した数の WorkItem を生成します。
下流の Python ノードは、上流の WorkItem の数に応じて同数 WorkItem が生成されます。
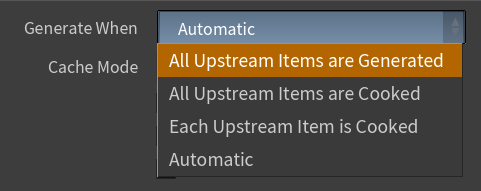
PDG のノードは、「Generate When」という項目が用意されています。
これはその名の通りで、どのような条件で WorkItem を Generate するかを指定します。
デフォルトは Automatic になっていて、 上流の Items が Generate されたタイミングで下流の WorkItem も生成されます。
つまり、Automatic の場合というのは、Cook しなくても(実行しなくても)WorkItem は
複数のノードをまたいで生成が可能ということになります。
このような、実行前にあらかじめ生成される WorkItem のことを StaticWorkItem と呼びます。
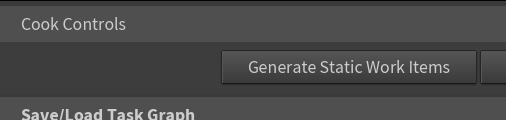
この StaticWorkItem は、TOP Networko の Cook Controls の「Generate Static Work Items」
を押すことで生成することが可能です。
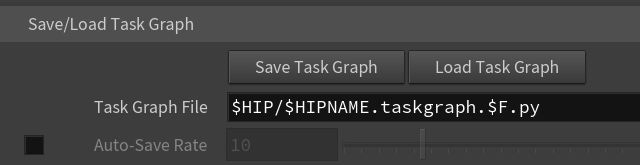
そして、この作成した TOP Network 内の StaticWorkItem は「Task Graph」と呼ばれていて
Python ファイルで保存が可能です。
(※ Generate しなければ保存はできない)

保存した TaskGraph を開くと、Python スクリプトで WorkItem をシリアライズし、
context.addWorkItem(s)
context.addWorkItemDependency(277,275,True,False)
context.addWorkItemDependency(278,276,True,False)
context.commitWorkItem(275)
context.commitWorkItem(276)
context.commitWorkItem(277)
context.commitWorkItem(278)
context に対して WorkItem を追加、そして Dependency(依存関係)を定義しています。
ここまで見たものから、PDG の構造を整理すると
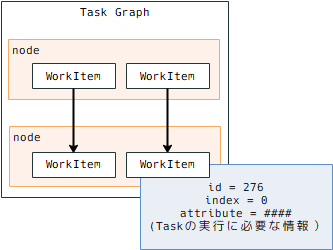
こんな感じになっています。
重要なのは、この Task Graph が持っているのは PDG で Task を実行するのに必要な情報のセットが
Task Graph として用意されているだけで、この WorkItem を実行させたり管理するものは含まれていません。
あくまでも TaskGraph には情報と依存関係があるだけです。
GraphContext
https://www.sidefx.com/docs/houdini/tops/pdg/GraphContext.html
この Task Graph (Task に必要なパラメーターの集合体)の Python に書かれている「Context」
というのが、この GraphContext です。
This object contains a reference to the graph and methods for running, pausing, canceling, etc. the work in the graph.
GraphContext は TaskGraph への参照を持ち、実行や停止、キャンセルなどのメソッドを持つ...とあります。
上で書いた TaskGraph というのが、TOP Network のデータ部分だとすると
この GraphContext は、 TOP Network 全体を管理するものになります。
ただし、「停止」したり「実行」したりする機能を GraphContext は持ちますが
あくまでも Graph 全体を管理することを求めているので
詳細な WorkItem 単位の処理やコントロールは GraphContext では行いません。
Scheduler
そしてようやくここからが本題です。
TOP Network 全体の WorkItem(実行対象)は TaskGraph として依存関係を含んだ
WorkItem の塊として GraphContext が持っていることがわかりました。
しかし、それらの WorkItem を「どのように実行するのか」という部分は持っていません。
そこで、その「実際に WorkItem をどう実行するのか」をつかさどるのが
Scheduler になります。
Scheduler は、Python クラスとして実装します。
実装方法は、あらかじめ用意された仮想関数をオーバーライドすることで、
特定のタイミングで特定の処理を実行できるようにしていきます。
https://www.sidefx.com/ja/docs/houdini/tops/schedulers_callbacks.html
どのような関数があるかはドキュメントを読むとして、
スケジューラーを理解するのに最も重要なのが onSchedule です。
onSchedule
onSchedule は、WorkItem が実行可能になったタイミングで呼ばれる関数です。
実行可能というのは、上流に WorkItem がある場合(レンダリングしてからその結果に何かをする等)上流の WorkItem が完了し、必要なファイルが揃った時のことを指します。
この onSchedule では、Ready になっている Task を実行したり(サンプルは実行している)
あるいは、他のレンダーファームなどに投げるときに
ファーム側の(Deadline 等)ジョブを生成して、ジョブを実行する部分を実装します。
この onSchedule 自体は並列で実行されるわけではなく、実行している PC で順番に実行されていきます。
そのため、この onSchedule 自体でサブプロセスなどで処理を実行させてしまうと
前回のように、Task は分散処理されず、1つずつ処理されてしまいます。
それだと意味がありません。
それを回避するには、 onTick と、scheduleResult を理解する必要があります。
scheduleResult
まず、各 WorkItem のステータスは、WorkItem 自身が持ちます。
各仮想関数で実装するときには、WorkItem のステータスを変更したり
結果を関数の戻り値として実装します。
https://www.sidefx.com/docs/houdini/tops/pdg/scheduleResult.html
onSchedule は、実行可能になったタイミングで呼ばれ
呼ばれた結果どうなったか、ステータスを返します。
Python Scheduler で作成した段階だと CookSucceeded というステータスになります。
このスケジュールを実行したときのステータスは、大きく分けて 2 段階になっていて
- Succeeded : スケジュールが完了して、WorkItem のジョブが投げられた状態
- CookSucceeded : スケジュールされたジョブが完了した状態
このようになっています。
なので、並列で処理を実行したい場合などは、 onSchedule では 「投げたよ、けど終わってないよ」というステータス Succeeded にしておく必要があります。
onTick
しかし、 スケジュールしただけでは投げっぱなしになってしまい
結果を受け取ることができません。
このような、どこかのファームで実行中の Task(WorkItem)の状態を監視して
終わったかどうか、エラーになっていないかを監視するのが onTick です。
onTick は、その名の通り、定期的に呼び出される関数です。
試しに 最低限の onSchedule 関数を スケジューラークラスに追加します。
def onSchedule(self, work_item):
self.workItems.append(work_item.id)
return pdg.scheduleResult.Succeeded
Ready になった WorkItem を self.workItems に積んでおきます。
この状態で実行したとしても、Cook は永遠に終わりません。
なぜならば、スケジュールを受け付けた状態から完了ステータスに移動していないからです。
なので、完了する処理を onTick 側に実装します。
def onTick(self):
from pdg import tickResult
print("onTick")
for ID in self.workItems:
print(f"Success: {ID}")
self.onWorkItemSucceeded(ID, -1, 0)
return tickResult.SchedulerReady
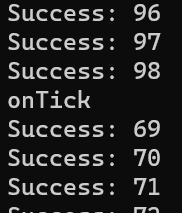
onTick は定期的に呼び出されるので、ID を積んである workItems を For でループして
積まれたものを完了にしていきます。
完了にしたい場合は onWorkItemSucceeded(ID,-1,0)を実行します。
この onTick を実装する上で重要なことは、
この onTick は、実行対象の work_item を引数として受け取るのではなく
定期的に実行しているという性質から、対象を引数で受け取れません。
なので、現在実行中の TOP Network の WorkItem(Generate 済の Task)を ID をキーにして
探しに行かなければいけません。
現在実行中の TOP Network は GraphContext で全体を管理します。
そして GraphContext 内の WorkItem は Graph という形で WorkItem とその依存関係を
管理しています。
なので、スケジューラー側から現在の WorkItem を確認したり状況を監視したい場合は
GraphContext から探せばいいわけです。
Scheduler クラスは、 context() で GraphContext を取得できるので、
def onTick(self):
from pdg import tickResult
print("onTick")
for ID in self.workItems:
work_item = self.context.graph.workItemById(ID)
print(work_item)
self.onWorkItemSucceeded(ID, -1, 0)
return tickResult.SchedulerReady
onTick 側でも work_item を取得することができました。
ただ、この Tick で Task を実行したとしても
この onTick も並列で実行されているわけではないので
積まれたタスクが順番に実行されるだけです。
なので、あくまでもこの onTick では、ステータスの監視や
ファームでの結果に応じて WorkItem のステータスを変更する部分を実装しなければいけません。
まとめ
だいぶ回りくどい内容になってしまいましたが
TaskGraph と Scheduler、そして WorkItem の関係性や役割がだいぶ見えてきました。
TOPNetwork では実行される Task は WorkItem という形に Generate されます。
そして Generate された WorkItem は、TaskGraph という形で管理されます。
管理されている情報は、GraphContext で全体を管理し
具体的な処理は Scheduler によって制御されます。
TaskGraph という実行するタスクの情報とその依存関係と、その情報をもとに実行したり制御する部分、どこで何をしているかが理解できてくると
TOP の見え方が変わってくる気がします。