コンポジションアークとは
前回、Stage/Layer/Spec を解説しましたが
その中でも度々でてきたのが「USD を合成する」という言葉。
初回 USD の概要でも
シーングラフ(描画要素を管理するためのデータ構造)を扱うことのできるライブラリ
であり
複数ソフトウェアをまたぐ、かつ大人数同時並行を行うために作成されたフォーマット
であると説明しました。
この「合成」処理こそ USD の強さの所以であり大きな特徴で
その合成方法のことを、 「コンポジションアーク」 と呼びます。
コンポジションの種類
とりあえずはどんな物があるのかを紹介。
| 名称 | 意味 |
|---|---|
| SubLayer | いわゆる import や include のようなもの。 あるレイヤーに対して、 指定のレイヤーを階層を含めて合成する |
| Inherits | ある プリム のアトリビュートなどを受け継いだ Prim を作る。 クラスの継承と同じ感じ。 サブレイヤーやリファレンスとは違いプリムの構造を プリムが「受け継ぐ」 |
| Variant | Switch 構造。 色パターンや形状パターンなど、 構造そのものをバリエーション定義して切り替えるスイッチをつけられる。 |
| Reference | ある Prim に対して、別レイヤーのツリー構造を埋め込む。 Prim に対して構造を子に埋めるというのがサブレイヤーとの違い。 (サブレイヤーは階層構造は維持したまま「マージ」する) |
| ペイロード | 効果はリファレンスと同じ。 違いは、読み込み時にフラグを入れるとロードを Off した状態でステージを開く。 大量の usda を合成しているときに一部だけ修正したい時など OFF にしてからシーンを開くことで シーンロードを短縮できる。 |
| Specialize | 基本的な挙動は継承と同様。しかし、リファレンスよりも弱い。 |
特殊化は基本あまり使わないので説明は割愛。(私もわかっていない)
計 6 個が USD の合成方法になります。
USD は、これらの「ルール」を組み合わせて1つのステージを構築していきます。
このコンポジションは、上の簡単な説明にあるとおり
それぞれ特徴があり、これらを組み合わせることで設計したパイプラインを実現していくことになります。
一応方法と簡単な説明だけだとわかりにくいので
詳細はこの記事の次から個別にサンプルも含めて紹介していく予定です
合成順序の決まり事
コンポジションアークには複数のルールがるということがわかりました。
しかし、ここで1つ疑問がおきます。
それが、
複数の合成方法が同時に存在していた場合はどうなるのだろう?
ということです。
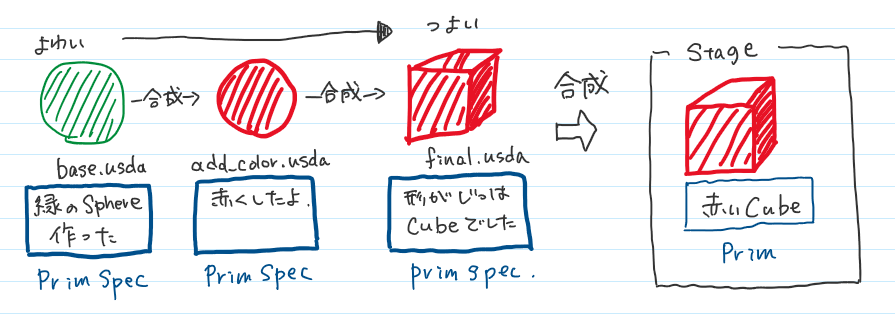
これは前回のプリムスペックの説明の時に書いた図で、合成方法は「サブレイヤー」によって
合成されている状態です。
コンポジションの合成は「レイヤー」と「レイヤー」のそれぞれの 意見(定義)
をどのように「調停」し、最終的なステージにするか...という話です。
(この個別の意見が、いわゆる「スぺック」とつくもの 例)プリムスペック、アトリビュートスペック等)
上の図の場合は、すべてがサブレイヤーによって合成されています。
その場合は、「後のほうが強い(後から読んだものが、元からあった情報を上書きする)」状態になります。
では、別々のコンポジションアークの場合はどうなるでしょうか。
コンポジションアークは、しばしば**「数術演算子」**にたとえられます。
足し算、引き算、かけ算、割り算とありますが、これらが同時にあった場合
どれから計算するかが決められているように
USD のコンポジションアークは、この合成順序が明確に決められています。
それが、「LIVRPS 原則」と呼ばれるものです。
LIVRPS 原則
LIVRPS の原則とは、
Local Inherits Variants Reference Payload Specialize の頭文字をとって LIVRPS となっていて
レイヤーとレイヤーの「合成時のオーバーラップ・コンフリクト」の解決を
どのような順序で合成方法を解決すればよいか Pixar 社の長い制作の歴史のなかで見いだされた最適解
の原則になります。
SdfPath について
この原則を説明する前に、SdfPath について説明します。
SdfPath とは、USD 内のシーングラフの階層構造をファイルパスのように表したもので、
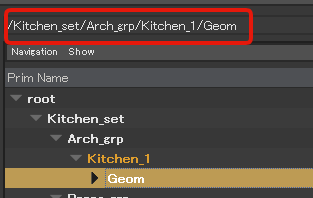
このように、 / をルートとして、指定のプリムまたはアトリビュートまでを
パスとして表し、この SdfPath を使用して値を取得したりセットしたり、プリムを指定したり
することができます。
そして、この LIVRPS の原則も この SdfPath で指定されるプリムやアトリビュートが
重複して指定された場合「どちらが有効になるのか」というのを示しています。
合成の解決は、この SdfPath が同じ場合のプリムやアトリビュートに対して行われていきます。
原則の説明を書きますが、多分個別のコンポ仕様を見てからのほうがわかりやすいかとおもいます。 個別の説明はもうしばらくお待ちください...
このあたりは、手島さんの CEDEC2017 スライドの 50-52 ページあたりがとてもわかりやすいです
解決のサンプル
まずこの LIVRPS は、L(Local)側が一番優先で、定義がなければ I V ... といった感じに評価していきます。
一番シンプルなパターン
#usda 1.0
class "TestClass"
{
custom bool testValue = False
}
def "hoge"
{
def "fuga" (
prepend inherits = </TestClass>
)
{
custom bool testValue = True
}
}
1 つの usda ファイル内に継承元のクラスがあり、それを継承したプリムがあり
そのプリムに対して値がセットされている例。
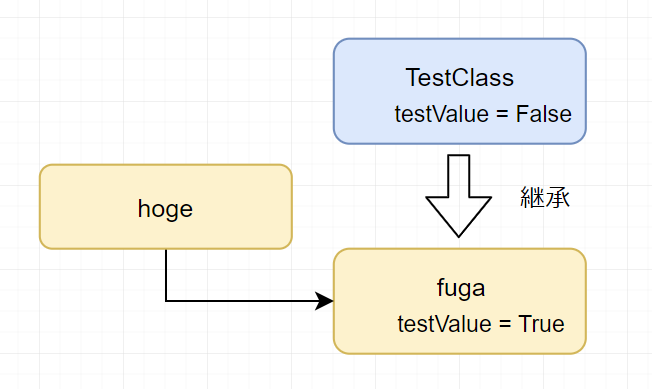 図にするとこんな感じです。(四角部分が Prim)
図にするとこんな感じです。(四角部分が Prim)
この状態でみると、
testValue が 2 つ定義されているのがわかります。
この場合に testValue を取得しようした場合、どちらが優先になるのか?というと、
「Local」のほうが「Inherits(継承)」より優先なので「True」が取得できます。
複数のコンポジションアークが重なった場合
#usda 1.0
class "TestClass"
{
custom bool testValue = False
}
def "hoge" (
prepend inherits = </TestClass>
)
{
}
もし、このように、 hoge プリムでなにも定義されていない場合
次は Inherits を解決しにいくので、この場合「False」が帰ってきます。
この例だととてもシンプルですが、では複数が重複した場合はどうなるでしょうか。
#usda 1.0
class "TestClass"
{
custom int testIntVal = 100
}
まず、 class.usda があり
#usda 1.0
(
defaultPrim = "hoge"
)
def "hoge"
{
def "fuga"{
custom int testIntVal = 10
}
}
こんな感じの refSample.usda
があったとします。
#usda 1.0
(
subLayers = [
@class.usda@,
]
)
def "hgoe"
(
prepend references = @refSample.usda@
)
{
def "fuga" (
prepend inherits = </TestClass>
)
{
}
}
それぞれを Reference と Inherits で合成します。
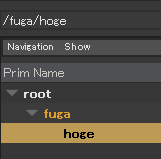
合成結果はこうなります。
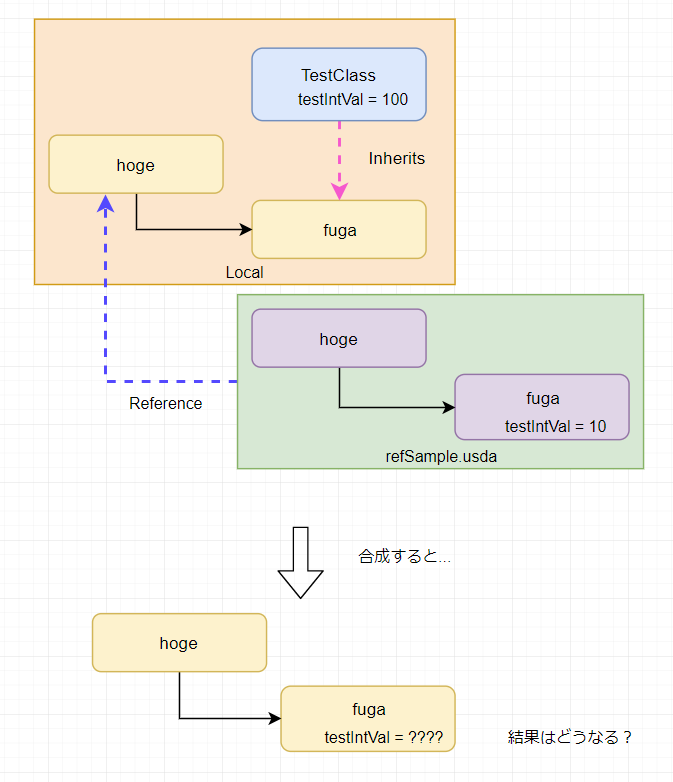
図に表すとこんな感じ。
このサンプルの場合 refSample の SdfPath /hoge/fuga の testIntVal = 10 と
class.usda の /TestClass の testIntVal = 100
が、同じアトリビュートになります。
これは、
継承によって合成している usda の hoge プリムが、 TestClass を「継承」して同じ値を持つため
/hoge/fuga に testIntVal = 100 がセットされた状態になるからです。
この場合はどうなるかというと、
Local にはない Inherits にはある(TestClass) Reference がある なので
LIVRPS の原則によって「Inherits(継承)」のほうが強いので、取得出来るのは「10」になります。
コンポジション先にまた別のコンポジションがあった場合
上の例だと、Local からみて Reference か Inherits かでしたが、
#usda 1.0
def "hoge"
(
prepend references = @referenceA.usda@
)
{
}
というファイルを開いた時、
#usda 1.0
(
defaultPrim = "hoge"
)
#usda 1.0
class "TestClass"
{
custom int testIntVal = 100
}
def "hgoe"
{
def "fuga"
(
prepend inherits = </TestClass>
prepend references = @referenceB.usda@
)
{
}
}
このような referenceA.usda があり
#usda 1.0
(
defaultPrim = "fuga"
)
def "fuga"
{
custom int testIntVal = 50
}
この usda を読んでいたとします。
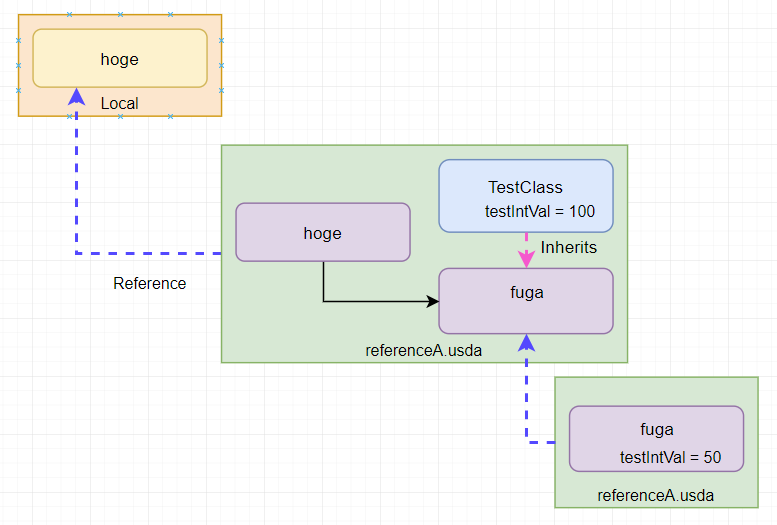
図にするとこんな感じ。
Reference の先に「Reference」と「Inherits」がある状態で、アトリビュートが重複しています。
このように「Reference」の先にまた別のコンポジションが存在している場合は
どういう扱いになるかというと
「R」を解決したあとに、また L I V R... というふうに原則の「L」を優先として
優先順序を解決していきます。
なので、今回の場合「Reference」があったさきに「Reference」と「Inherits」があったら
「Inherits」が優先になるので「100」が取得できます。
なお、今回はアトリビュートでの合成を例にしましたが、プリムに関しても同様の解決方法になります。
まとめ
ここまで見たとおり、USD のコンポジションは
一貫したルールによってプリムやアトリビュート定義の
これは、階層が深くなっていったりコンポジションの関係性複雑になっていっても
一貫した USD のコンポジションの絶対ルールであり
このルールが厳密かつ一貫しているからこそ「強力かつ柔軟」な合成を可能にしています。
たとえ、意図しない合成(間違ってアトリビュートやプリムが上書きされた場合など)が発生した
場合であっても、原則によって処理されるので
原則に反って問題のオーバーラップなどを解決しにいくことができます。
また、すべての USD の合成は非破壊によって行われるのでデータが損なわれることはありません。
このコンポジションアークの機能を組み合わせると、
多くのパイプラインに対応することが可能になり
同時作業時のデータコントロールや、いわゆる「コンカレントパイプライン」とよばれる
あらゆる工程の作業者が同時並行で作業するようなパイプラインを実現することができます。